Imagine a world where machines not only hear your words but understand them with astonishing precision. This astonishment is made possible by the ingenious design of Speech Recognition Acoustic Models. Welcome to the wondrous world of Speech Recognition Acoustic Models, where speech becomes a universal language comprehended by silicon minds. The futuristic vision is made possible by the intricate workings of speech recognition acoustic models, the unsung heroes behind the scenes of voice assistants, transcription services, and a myriad of other applications. Speech recognition acoustic models are a vital component of automatic speech recognition (ASR) systems. They play a key role in converting spoken language into written text. Now let us deep dive into the concept pf this wonderful topic.
What is Speech Recognition – Acoustic model?
Automatic Speech Recognition (ASR) is a technology that enables machines to convert spoken language into written text. This technology has numerous applications including voice assistants (like Siri, Alexa), transcription services, customer service applications, and more. It’s essentially a mathematical model that learns to understand the relationship between audio input (speech signals) and the corresponding linguistic units, such as phonemes or sub-word units. Speech recognition acoustic models have evolved significantly with the advent of deep learning. Models like Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) are widely used in acoustic modelling. These models are at the core of technologies like voice assistants (e.g., Siri, Alexa), transcription services, and more. They play a crucial role in enabling machines to understand and interact with spoken language.
Some interesting insights of this model:
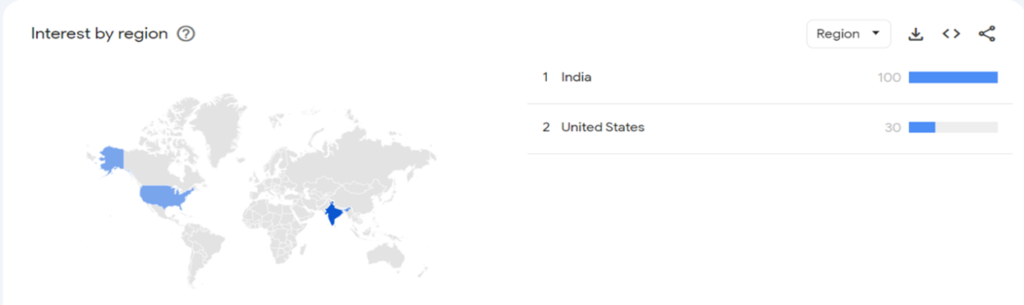
In the following attachments, you can observe that the given model has been searched for an average of 60 times every month for the past 2 years. India and USA are the 2 countries mostly dealing with this model.

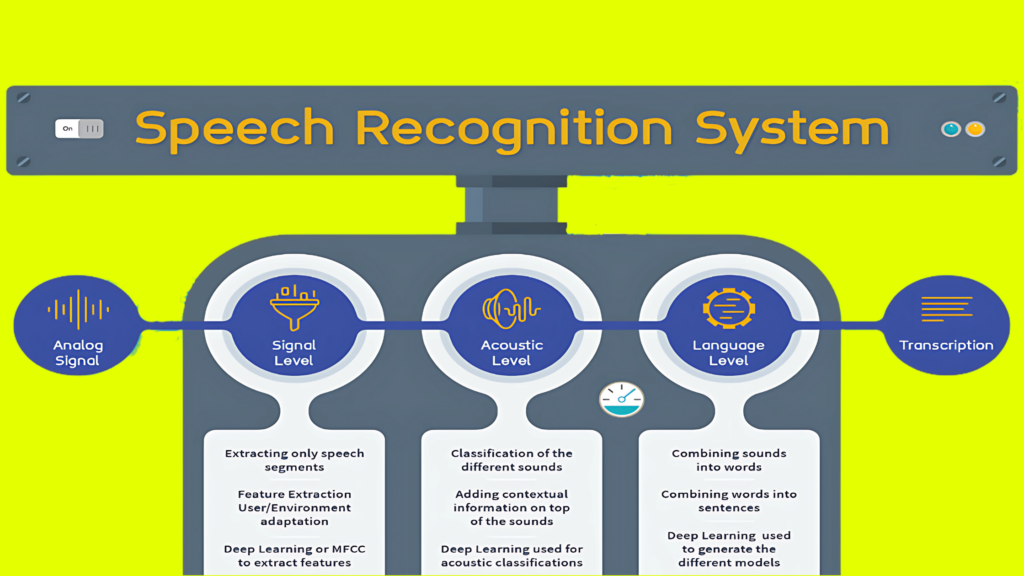
How Speech Recognition Acoustic model works?
The following steps are followed:
1.Audio Input:
- The process begins with an audio input, which is usually a waveform representing the sound.
2. Feature Extraction:
- The first step is to convert the raw audio waveform into a format that’s more suitable for machine learning algorithms. This often involves extracting features like Mel Frequency Cepstral Coefficients (MFCCs) or filterbanks.
3. Deep Learning Architecture:
- Many modern speech recognition acoustic models employ deep learning techniques, especially Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs). These models are trained on large datasets containing pairs of audio inputs and their corresponding transcriptions.
4. Learning Relationships:
- During training, the model learns to predict the most likely sequence of phonetic units (such as phonemes or sub-word units) that correspond to the audio input. It does this by analysing the relationships between the extracted features and the phonetic units.
5. Probabilistic Output:
- The model outputs a sequence of probabilities for different phonetic units at each time step. The sequence represents the likelihood of each phonetic unit occurring given the input audio.
6. Integration with Language Model and Lexicon:
- The output from the acoustic model is combined with information from a language model and a lexicon. The language model provides information about the likelihood of word sequences, while the lexicon maps words to their corresponding phonetic representations.
7. Decoding:
- Using algorithms like the Viterbi algorithm, the system searches for the most probable sequence of words or phonetic units that best matches the observed audio.
8. Final Transcription:
- The result of the decoding process is the final transcription of the spoken input.
9. Adaptability and Fine-tuning:
- Some systems have the capability to adapt or fine-tune the model based on user-specific data. This helps in improving accuracy for individual users over time.
10. Feedback Loop:
- In applications like voice assistants, user interactions and feedback are often used to retrain and improve the speech recognition model.
Overall, a speech recognition acoustic model plays a crucial role in understanding the acoustic characteristics of speech and converting it into a form that can be processed by a computer algorithm to generate accurate transcriptions.
Speech Recognition model code:
Now we are going to see codes with the use of popular ASR libraries or APIs
Google Speech-to-Text API:
we will be working with codes with the use of Python Library SpeechRecognition,which wraps various ASR(Acoustic Speech Recognition) engines, including Google Web Speech API, Sphinx, etc.
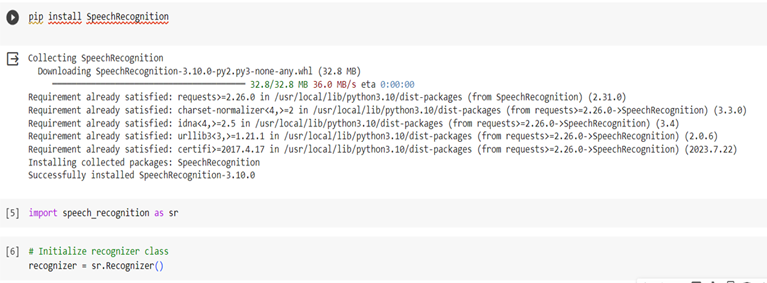
In the above code, SpeechRecognition library is installed.
The module speech_recognition is imported with alias sr. The Recognizer class is part of the SpeechRecognition library in Python. This class is used to perform various operations related to speech recognition, such as listening for audio input from a microphone, recognizing speech from an audio source, and working with different speech recognition engines.
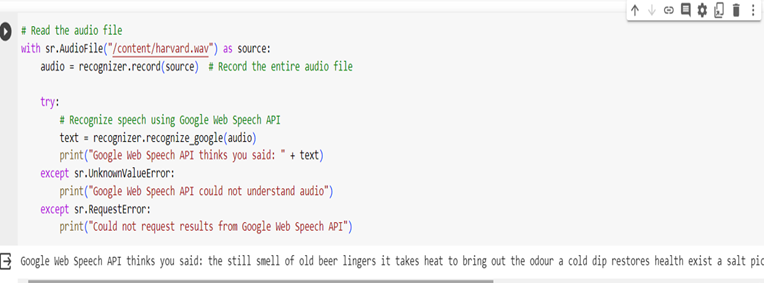
Method record is used to record audio from the source. recognize_goggle, this method recognizes speech using the Google Web Speech API.If audio is not understandable error will raise. Google Web Speech API, also known as the Web Speech API, is a browser-based API that allows web developers to integrate speech recognition capabilities into their web applications. It enables applications to convert spoken language into text, making it useful for tasks like voice commands, transcription services, and more.
Hugging Face’s transformers Library:
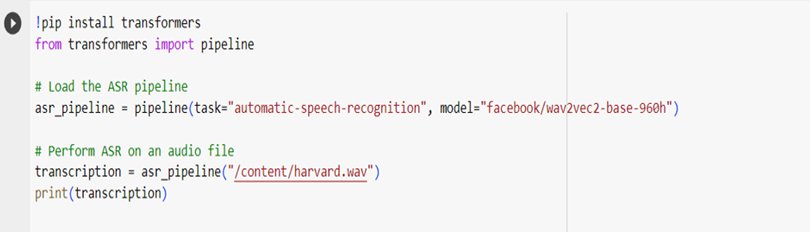
‘Transformers’ library is used here to create pipeline where task and model must be taken and thus ASR is performed on audio file.
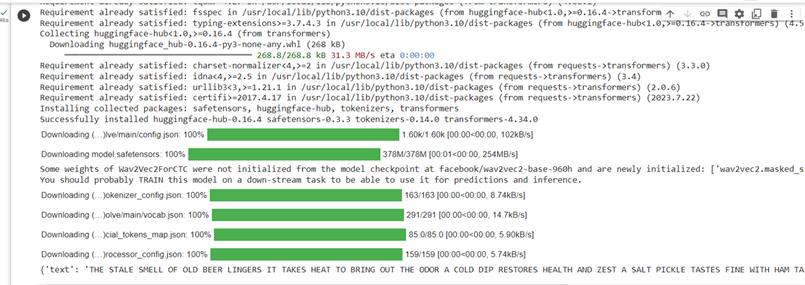
This is the output we got and the text from the audio is extracted.
Language Model in Speech Recognition:
In speech recognition, a language model plays a crucial role in improving the accuracy and fluency of the recognized text. It provides additional context to help the system make more accurate predictions about the next word or sequence of words in the transcription.
Important properties of language model in speech recognition:
- The language model takes the output of the acoustic model (i.e., a sequence of words or units) and assigns probabilities to different sequences of words.
- It helps in choosing the most likely sequence of words based on the context provided by the language model.
- For example, given the sequence “I want to eat a slice of…”, the language model might assign a higher probability to the word “pizza” compared to “banana”.
The language model can be built using various approaches:
- N-gram Models: These models estimate the probability of a word given its context by counting occurrences in a training corpus. They are based on the probability of the current word given the previous (n-1) words.
- Neural Network-based Models: Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTM) networks, and Transformers can be used to learn the probability distribution over sequences of words directly from data.
- Statistical Language Models: These models are based on probability theory and statistical techniques. They can be trained on large text corpora.
- Transformer-based Models: Models like GPT-2, GPT-3, and similar architectures can be used as powerful language models.
- Customized Models: Depending on the specific application, you might choose to create a domain-specific language model.
By combining an acoustic model with an appropriate language model, you can significantly improve the accuracy and fluency of transcriptions in a speech recognition system.
Sample code to understand the language model for speech recognition:
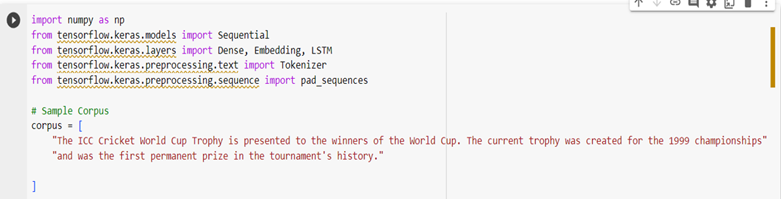
We have imported required deep learning libraries and then under the variable corpus we have given a text.

Tokenization to be done where we use the Tokenizer from Keras to convert text into sequences of integers. Then Input Sequences and Labels is created where we create sequences of increasing length from the tokenized text. These sequences are used as input, and the next word in each sequence is used as the label. Model is Defined where we define a simple LSTM-based neural network.
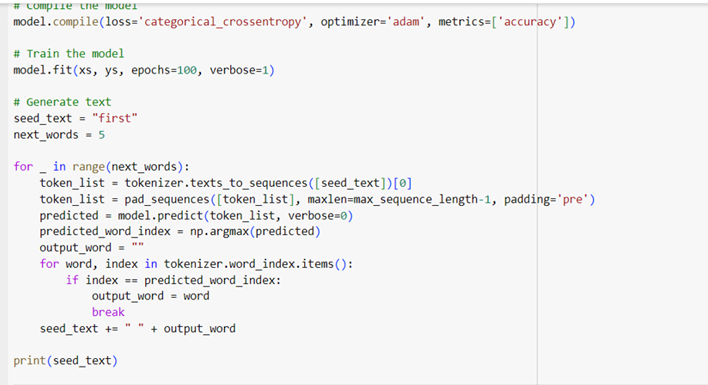
Model Compilation is done where we compile the model with suitable loss function and optimizer.Model is trained where we train the model on the input sequences and labels.Text Generation: We use the trained model to generate text. Starting with a seed text, we predict the next word and append it to the seed text.
Model is trained with 100 epochs and we got good accuracy of 93.75% with loss of 0.7415. As we can see we have got next 5 predicted words as ‘icc cricket world cup trophy’.
Acoustic wave simulation
Acoustic wave simulation is a technique used in the development and testing of speech recognition systems.
Let us see how acoustic wave simulation is relevant to speech recognition:
1. Data Augmentation:
- Simulated acoustic data is often used to augment training data for speech recognition models. By adding artificially generated acoustic variations to the training set, the model becomes more robust to real-world acoustic conditions.
2. Noise and Environmental Variation:
Simulating different acoustic environments (like noisy environments, reverberant rooms, etc.) helps in training the model to be more robust to different real-world scenarios.
3. Speaker Variability:
Simulation can be used to introduce variations in speaker characteristics, like pitch, accent, or gender. This helps the model generalize better across different speakers.
4. Adversarial Attack Simulation:
In security-related scenarios, simulating adversarial attacks helps in making speech recognition systems more secure against intentional distortions.
5. Testing and Evaluation:
Simulated data is often used in testing and evaluating speech recognition systems. This allows researchers and developers to assess the performance of their models under controlled conditions.
Use of Speech Recognition Acoustic Model
1. Voice Commands and Assistants:
- Acoustic models are used in voice-activated systems like Siri, Google Assistant, Amazon Alexa, and others. They allow users to interact with devices and perform tasks using spoken commands.
2. Transcription Services:
- Acoustic models are used in transcription services to convert spoken audio (e.g., meetings, interviews, lectures) into text. This is valuable for tasks like note-taking, subtitling, and more.
3. Accessibility Services:
- They provide a means for individuals with disabilities to interact with devices, enabling them to access technology and information.
4. Customer Service and Support:
- Many companies use ASR systems in their customer service operations, allowing customers to interact with automated systems for tasks like checking account balances, making reservations, and more.
5. Voice Search in Search Engines:
- Search engines use ASR to allow users to perform voice searches. This is especially common in mobile devices and smart speakers.
6. Automated Call Centres:
- ASR models are used in call centres to automate certain tasks, such as routing calls or gathering information from callers.
7. Medical Transcription:
- In healthcare, ASR is used for transcribing medical dictations, which helps in creating patient records and documentation.
8. Language Learning Applications:
- ASR models can be used in language learning apps to assess and improve pronunciation and fluency.
9. Smart Home Systems:
- ASR is used in smart home automation systems, allowing users to control various aspects of their homes through voice commands.
10. In-Car Systems:
- Automotive companies use ASR for in-car infotainment systems and navigation, allowing drivers to control various functions hands-free.
11. Assistive Technology:
- ASR can be used to provide a means of communication for individuals with speech impairments.
12. Voice Analytics:
- ASR is used in voice analytics platforms to analyze customer interactions in call centers for sentiment analysis, compliance monitoring, and more.
13. Security and Authentication:
- ASR models can be used for speaker verification and authentication in security applications.
14. Research and Development:
- Researchers use acoustic models to advance the state-of-the-art in speech recognition, exploring new techniques and architectures.
Acoustic models are trained on vast amounts of labelled audio data to accurately map acoustic features to phonetic representations. They are usually combined with language models to form a complete speech recognition system.
Conclusion
By now we have got fair idea of what speech recognition acoustic model is, what language model for speech recognition is, it’s uses and their practical implementation using python codes. In conclusion, the speech recognition acoustic model stands as a cornerstone in the realm of automatic speech recognition (ASR) systems. Through its sophisticated understanding of acoustic features, it transforms spoken language into written text, enabling a multitude of applications across various industries. In summary, the speech recognition acoustic model not only empowers technology with the ability to comprehend and respond to spoken language, but also drives innovation across industries, revolutionizing the way we interact with machines and enhancing accessibility for all. If you liked my blog then please upvote and provide your feedback in the comment section.