
Just Imagine teaching your pet new tricks without direct commands but by rewarding its good attempts and gently discouraging the not-so-great ones. This process, based on Feedback and rewards, is at the heart of Reinforcement Learning (RL), a captivating field in machine learning. Does it not seem interesting? Imagine an algorithm that not only learns from its experiences but does so by emulating the way humans make decisions – by weighing the potential outcomes and choosing the most promising path. Picture a computer program that learns to play complex video games. This is the magic of DQNs, which are a type of neural network architecture used in reinforcement learning. Welcome to the world of Deep Q-Networks, where neural networks play the game and play it exceedingly well. Want to know more? Let us dive deep into this in this blog.
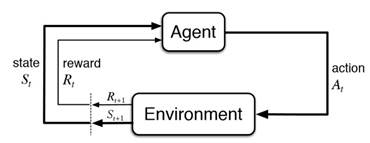
What is Deep Q Networks?
Deep Q-Networks (DQNs) are a type of neural network architecture used in reinforcement learning. A DQN is a neural network that takes in the state of an environment as input and outputs an estimate of the expected future rewards for each possible action that can be taken in that state. Difficult to understand, right?
Let me clear you with a simple example. Imagine you have a computer program that’s learning to play a video game. It is not being told exactly what to do, but it’s figuring things out on its own. Now, instead of just knowing what is happening on the screen, this program is trying to predict which actions will give it the best score. This is where Deep Q Networks (DQNs) come in. They are like the brains of this program. They are really good at learning patterns, so they try to figure out the best actions to take based on what the program is seeing. But here’s the cool part: this brain (DQN) doesn’t just memorize what to do in every single situation. It learns and gets better over time by making mistakes and learning from them.
I hope you got some idea about this very interesting topic.
Now let us check some interesting facts about this Concept.
This word, Deep Q Networks, has been searched 80 times on average every month for the last two years worldwide.
China comes in first place when it comes to game development, and undoubtedly, China stands 1st in using this Concept on an average of 80 times per month.

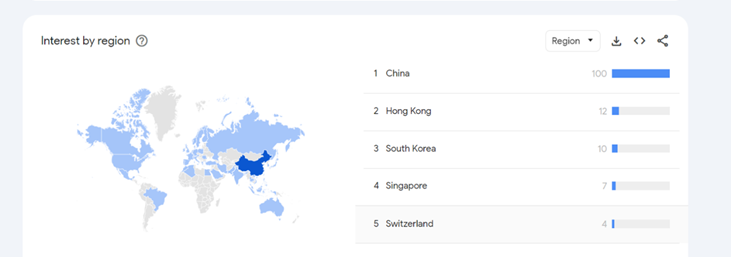
The above images are the facts to know about this interesting topic.
Let us now understand the concepts behind Deep Q Networks.
The concepts behind Deep Q-Networks (DQNs) involve a combination of deep learning and reinforcement learning. Here is a breakdown of the key concepts:
1. Reinforcement Learning (RL):
- At its core, an agent learns a sequence of decisions by interacting with an environment. The agent, based on its action, gets rewards or penalties.
2. Q-Learning:
- Q-learning is a foundational algorithm in reinforcement learning. It involves maintaining a table (Q-table) that estimates the value of taking a particular action in a particular state. However, in environments with large state spaces, using a table becomes infeasible.
3. Action-Value Function (Q-Function):
- Action value function Q(a,s) represents the expected return (cumulative future rewards) of taking action “a” in the state “s” and then following the optimal policy thereafter.
4. Deep Neural Networks:
- Deep learning involves training neural networks with multiple layers (deep architectures) to learn and represent complex relationships within data. DQNs utilize deep neural networks to approximate the action-value function.
5. Approximation of Q-Function:
- Instead of using a Q-table, DQNs use a neural network to approximate the Q-function. The neural network takes the state as input and outputs the estimated Q-values for each action.
6. Experience Replay:
- Experience replay is a technique used in DQNs to improve the efficiency of training. Instead of using each observation only once, the agent stores experiences (state, action, reward, next state) in a replay buffer. During training, the agent samples batches from this buffer to break the temporal correlation in the data.
7. Target Network:
- DQNs use two separate neural networks: the online network and the target network. The online network is updated at every time step, while the target network is periodically updated with the weights of the online network. This helps in reducing the target overestimation bias that can be present in Q-learning.
8. Loss Function and Training Process:
- The loss function for training a DQN is usually the mean squared error between the predicted Q-values and the target Q-values. The training process involves iteratively interacting with the environment, collecting experiences, and updating the Q-network using gradient descent based on the loss function.
Let us now understand the architecture of Deep Q Networks:
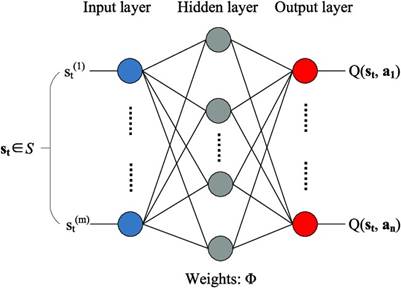
1. Input Layer:
- The input layer of a DQN receives the state information from the environment. This could be visual data (like pixels from a game screen) or numerical features, depending on the nature of the problem.
2. Deep Neural Network Layers:
- Following the input layer, there are one or more hidden layers in the neural network. These layers are responsible for learning the complex relationships between the state information and the estimated Q-values for each action.
3. Activation Functions:
- Each hidden layer is typically followed by an activation function (e.g., ReLU – Rectified Linear Unit), which introduces non-linearity into the network, allowing it to approximate more complex functions.
4. Output Layer:
- The output layer of the DQN has as many neurons as there are possible actions in the environment. Each neuron outputs an estimated Q-value for a specific action.
5. Output Activation Function:
- Depending on the problem, the output layer may or may not have an activation function. For instance, in some cases, a linear activation function is used for the output layer.
6. Experience Replay Buffer:
- This is not a part of the neural network itself but an important component in training DQNs. It is a memory buffer that stores experiences (state, action, reward, next state) which are sampled during the training process. This helps in breaking the temporal correlation in the data.
7. Target Network:
- DQNs use two separate networks: the online network and the target network. The online network is used to select actions during gameplay, while the target network is used to estimate the value of those actions
8. Loss Function:
- The loss function used for training a DQN is usually the mean squared error between the predicted Q-values and the target Q-values.
9. Optimizer:
- An optimizer like stochastic gradient descent (SGD) or more advanced ones like Adam are used in updating weights.
Deep Q Networks in the Gaming World:
Deep Q-Networks (DQNs) are powerful algorithms in reinforcement learning that have shown exceptional performance in playing video games. Here’s how DQNs work in the context of gaming:
1. State Representation:
- In a game, the state is a snapshot that represents the current situation, including the positions of objects, the player’s position, scores, etc. This state is fed into the DQN.
2. Action Selection:
- The DQN processes the state through its neural network layers, producing estimated Q-values for each possible action. These Q-values represent the expected future rewards for taking each action in the current state.
3. Exploration and Exploitation:
- The agent needs to balance exploration (trying out different actions to learn more about the environment) and exploitation (choosing the best-known action to maximize rewards). This is typically handled using an exploration strategy, such as an epsilon-greedy policy. Initially, the agent explores more (higher epsilon), gradually shifting towards exploitation as it gains more experience.
4. Taking an Action:
- Based on the estimated Q-values, the agent selects an action. This action is then executed in the game environment.
5. Receiving Feedback:
- After taking an action, the environment responds with a new state and a reward. The reward reflects the immediate Feedback on the goodness of the action taken. It could be positive (rewarding), negative (penalizing), or zero.
6. Experience Replay:
- The state, action, reward, and next state are stored in a replay buffer. This buffer is periodically sampled during training. Experience replay helps in breaking the temporal correlation in the data and stabilizes the learning process.
7. Training the DQN:
- The DQN is trained to approximate the optimal action-value function using a loss function, typically the mean squared error between predicted Q-values and target Q-values. The target Q-values are calculated using the Bellman equation.
8. Target Network:
- A separate target network is used to calculate target Q-values. This network has the same architecture as the main DQN but is updated less frequently. It provides more stable target values during training.
9. Iterative Learning:
- The agent iteratively repeats the process of selecting actions, receiving rewards, storing experiences, and updating the DQN’s weights. This process allows the agent to learn effective strategies for playing the game.
10. Convergence:
- With enough iterations and training, the DQN learns to predict the best actions for different states in the game. It refines its predictions over time, ultimately leading to improved gameplay performance.
Now, we will see a sample code of Cart-Pole. Before that, let us understand what this Cart-Pole is:
The CartPole environment is a classic benchmark problem in the field of reinforcement learning. It is provided by the OpenAI Gym, which is a widely used toolkit for developing and comparing reinforcement learning algorithms. In the CartPole environment, there is a pole standing upright on top of a cart. The goal of the agent is to keep the pole balanced by applying forces to the left or right, causing the cart to move. The agent receives a positive reward for each time step that the pole remains upright. The episode ends if:
- The pole angle is more than ±12 degrees from vertical.
- Movement of cart 2.4 units from centre.
Let us see the code:
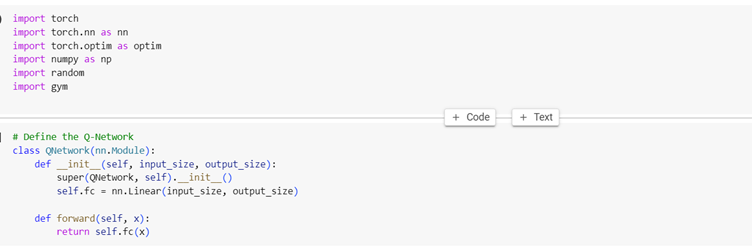
1. Importing Libraries: Here, we import the necessary libraries, the OpenAI Gym library, for accessing the CartPole environment.
2. Defining the Q-Network: This defines a simple feedforward neural network. It takes input_size as input (the number of features in the state space) and produces output_size outputs (the Q-values for each action). In this case, input_size is 4 (CartPole has 4 state features) and output_size is 2 (two possible actions: left or right).
3. Defining the DQN Agent: The DQNAgent class is initialized with the size of the state space (state_size), the number of possible actions (action_size), the learning rate for the optimizer (learning_rate), and the discount factor (gamma).
4. Selecting Actions: The select_action method implements an epsilon-greedy strategy. With probability epsilon, a random action is selected. Otherwise, the action with the highest Q-value from the Q-network is chosen.
5. Training the Agent: The train method performs a single step of training. It computes the Q-value for the chosen action, computes the target Q-value using the Bellman equation, and minimizes the loss using a Huber loss function (smooth L1 loss).

6. Hyperparameters: These are the hyperparameters for the DQN agent and training process.
7. Initializing Environment and Agent: This creates the CartPole environment and initializes the DQN agent.

8. Training Loop: This is the main training loop. It iterates over episodes, where each episode is a run of the environment. Within each episode, the agent interacts with the environment, selects actions, and updates the Q-network.
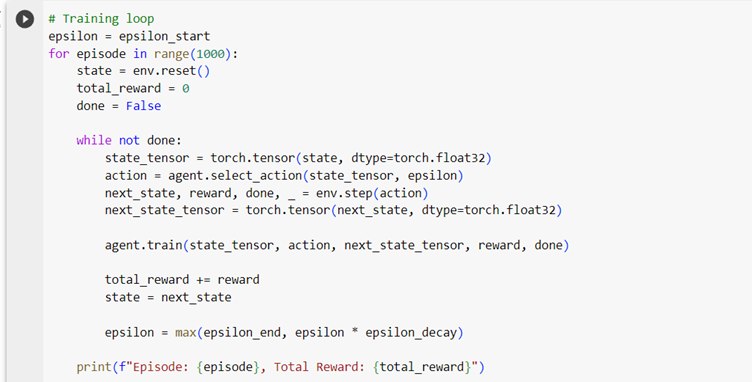
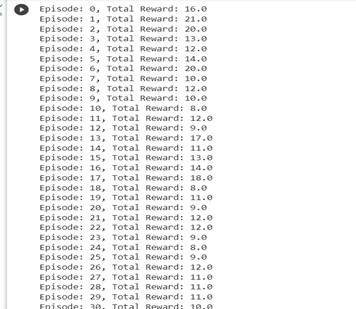
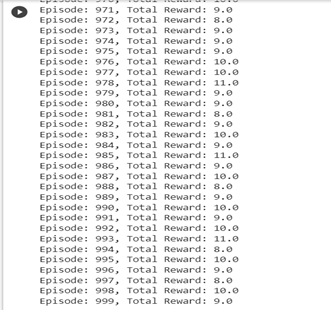
When you see “total reward: 10”, it means that in that particular episode, the agent managed to keep the pole upright for 10 time steps before the episode terminated.
Conclusion
Now we have got a fair idea of this Concept. We have seen what Deep Q Networks means, the logic behind it, its application and finally, a sample code on a Cart-Pole environment. In conclusion, Deep Networks represented a major milestone in reinforcement learning by demonstrating the feasibility of using deep neural networks to tackle complex tasks. This makes it a powerful tool for solving a wide array of real-world problems. Thanks for your patience. If you genuinely like this blog, provide your Feedback in the comment section.