
Welcome to the fascinating world of generative models in recommender systems, where the power of artificial intelligence meets the art of personalization! Generative models for recommendation systems – an innovative approach that surpasses traditional algorithms to craft personalized suggestions like a master artist painting vibrant portraits of your interests
Imagine a recommender system that not only understands your preferences but has the creative power to implore entirely new possibilities adapted just for you. In this domain, data is not just analysed; it becomes a canvas on which these models paint a rich tapestry of novel and diverse recommendations, promising a journey of delightful discoveries at every turn. Let us begin on this fascinating exploration of generative models, where the boundaries of personalized recommendations are redefined, and the art of suggestion reaches unprecedented heights. Let us dive deep into these concepts in this blog. Read the entire blog to gain immense knowledge on this topic.
What is Generative model for Recommendation system?
Generative models for recommender systems are a class of machine learning models that aim to understand the underlying patterns in user-item interaction data and generate personalized recommendations. This means that generative models not only predict user preferences for existing items but also have the ability to generate entirely new item recommendations that are tailored to each user’s unique preferences.
The fundamental idea behind generative models is to learn the patterns and relationships within the user-item interaction data in a way that allows the model to create new, realistic examples.
- Personalization: Generative models can create highly personalized recommendations, catering to individual tastes and preferences, as they capture the user’s unique interaction patterns.
- Novelty: Unlike traditional models that often rely on popular items, generative models can suggest novel and diverse items, enhancing user discovery.
- Adaptability: Generative models can adapt to changing user preferences over time, ensuring the recommendations remain relevant and up-to-date.
- Data Efficiency: Generative models can handle sparse data more effectively and make better use of limited user-item interactions.
Let us check some facts about Generative models:
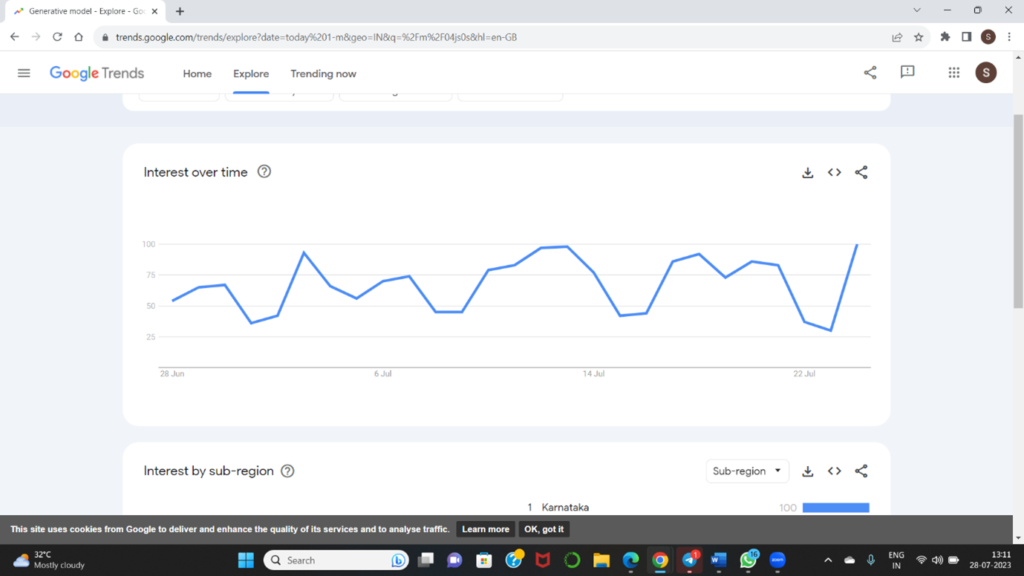
This is searching trends of Generative Model in India for the past 30 days. Daily average search of this topic is more than 75 times. This is how the world is proceeding with the concept of Generative Model.
Let us check the states where several companies are working with this concept.
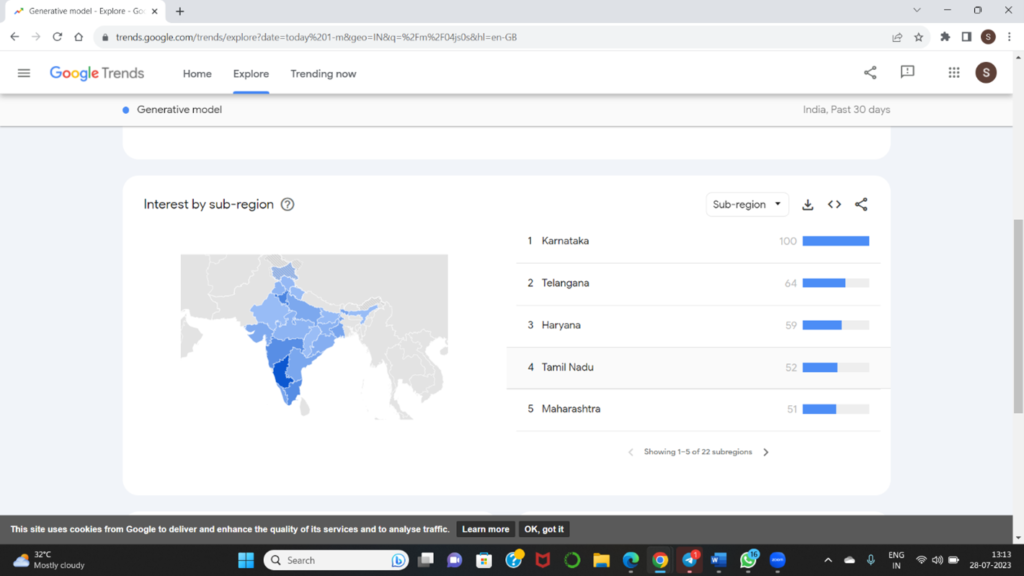
As we can see Karnataka and Telangana are the states leading from front.
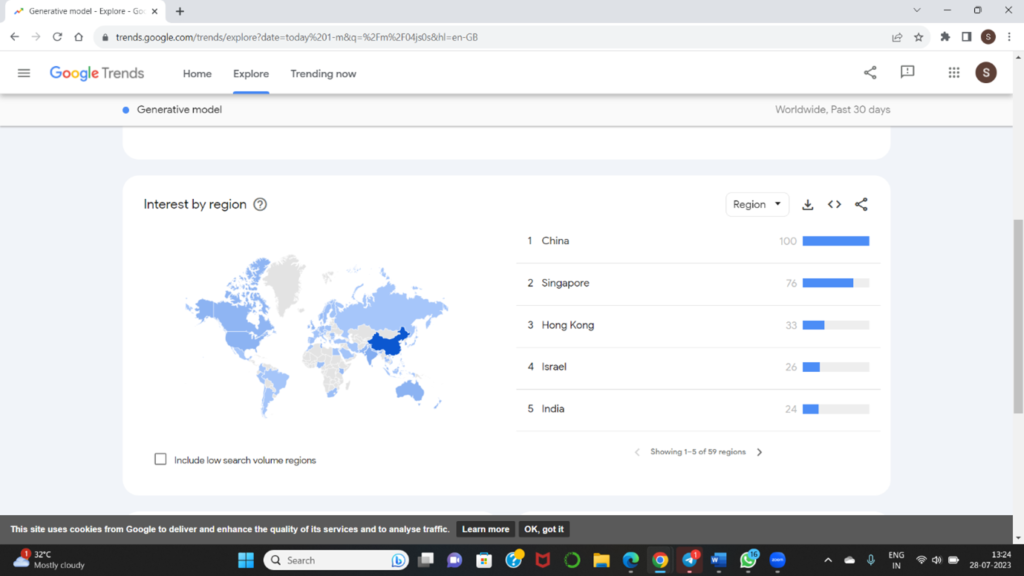
These are the countries searched the most of this topic in the last 30 days. China, Singapore leading the search history.
We have 3 popular generative model: Variational Autoencoder (VAE) and Generative Adversarial Network (GAN), Autoregressive model, these can grasp the intricate relationships between users and items. They create a multidimensional representation of preferences, allowing for a better understanding of individual tastes and preferences.
Let us discuss VAE and GAN in detail.
Variational Autoencoder (VAE):
It is a generative AI algorithm that uses deep learning to detect anomalies, remove noise and generate new content. It is used to learn a probabilistic mapping of input data into a lower-dimensional latent space, and from that latent space, generate new data that resembles the original input.
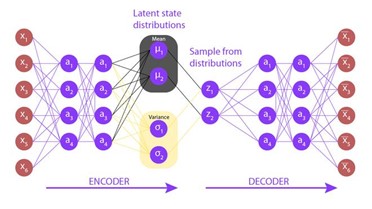
The basic structure of a Variational Autoencoder consists of two main components:
1.Encoder: The encoder takes the input data (e.g., user-item interactions in the case of recommender systems) and maps it into a latent space that is lower dimension space. The output of the encoder is not a deterministic encoding, but rather a probability distribution of the latent variables.
Now Question arises PCA and Encoder same?
No, as PCA learns linear relationship and Encoder learns Non-Linear relationship.
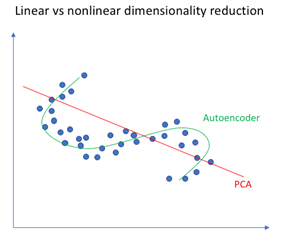
From the figure we can see that PCA is learning the data having linear structure and Encoder is learning the data having complex structure. Once Encoder uses linear activation functions then in that case PCA=Encoder.
2.Decoder: The decoder takes a sample from the latent space (i.e., latent variables) and reconstructs the original input data from that sample. Like the encoder, the decoder also produces a probability distribution for the output data.
Let us now see what VAE for Recommendation system is:
Here is a high-level overview of how a VAE-based recommender system works:
1.Data Representation:
Convert user-item interactions into a matrix format, where rows represent users, columns represent items, and the entries contain user-item interactions (e.g., ratings, binary indicators, or other relevant metrics).
2.VAE Architecture:
- Encoder (Q): The encoder network takes user-item interactions (or their embeddings) as input and maps them to a lower-dimensional latent space, where each user and item are represented as continuous vectors.
- Decoder (P): The decoder network takes a point in the latent space (user and item embeddings) and reconstructs the user-item interactions from it, aiming to reconstruct the original data accurately.
3.VAE Training:
- The VAE is trained to minimize the reconstruction loss, which measures how well the decoder can reconstruct the original user-item interactions from the latent space.
- Additionally, VAEs incorporate a regularization term (KL-divergence) to encourage the latent space to follow a prior distribution (usually a Gaussian distribution) and improve the interpretability of the latent representations.
4.Recommendation Generation:
- After training, the VAE can be used to generate recommendations for users.
Let us check one example code of Variational Encoder. We are considering Movies Lens dataset and working with it to develop the Recommendation model.
First, we install required packages.
| ! pip install tensorflow –upgrade import numpy as np import pandas as pd from keras.layers import Input, Dense, Lambda from keras.models import Model from keras import backend as K from keras import objectives from sklearn.model_selection import train_test_split |
Load data and do preprocessing.
| data = pd.read_csv(‘/content/ratings.csv’) # Preprocess the data to create the user-item interactions matrix user_item_matrix = data.pivot(index=’userId’, columns=’movieId’, values=’rating’) user_item_matrix = user_item_matrix.fillna(0) # Convert the user-item interactions matrix to a NumPy array user_item_matrix_array = user_item_matrix.to_numpy() # Spliting the data into train and test train_data, test_data = train_test_split(user_item_matrix_array, test_size=0.2, random_state=42) |
Defining parameters, Building Encoder, Decoder and combining encoder and decoder to build the model.
# Define VAE parameters
original_dim = user_item_matrix_array.shape[1] # Number of items (features)
latent_dim = 32 # Number of latent dimensions
batch_size = 64
epochs = 50
# VAE encoder architecture
x = Input(shape=(original_dim,))
h = Dense(64, activation=’relu’)(x)
z_mean = Dense(latent_dim)(h)
z_log_var = Dense(latent_dim)(h)
# Reparameterization trick
def sampling(args):
z_mean, z_log_var = args
epsilon = K.random_normal(shape=(K.shape(z_mean)[0], latent_dim), mean=0., stddev=1.0)
return z_mean + K.exp(z_log_var) * epsilon
z = Lambda(sampling)([z_mean, z_log_var])
# VAE decoder architecture
decoder_h = Dense(64, activation=’relu’)
decoder_mean = Dense(original_dim, activation=’sigmoid’)
h_decoded = decoder_h(z)
x_decoded_mean = decoder_mean(h_decoded)
# Define VAE custom loss function (binary cross-entropy + KL divergence)
def vae_loss(x, x_decoded_mean):
xent_loss = objectives.binary_crossentropy(x, x_decoded_mean)
kl_losss = – 0.5 * K.sum(1 + zlog_var – K.square(z_mean) – K.exp(zlog_var), axis=-1)
return xent_loss + kl_losss
# Compile VAE model
vae = Model (x, x_decoded_mean)
vae.compile(optimizer=’adam’, loss=vae_loss)
Training the model.
# Train the VAE model
vae.fit(train_data, train_data,
shuffle=True,
epochs=epochs,
batch_size=batch_size,
validation_data=(test_data, test_data))
# Use the trained VAE model to generate recommendations for a user
def generate_recommendations(user_data, vae_model):
return vae_model.predict(user_data)
# Example usage
user_id = 0
user_data = np.expand_dims(user_item_matrix_array[user_id], axis=0)
recommendations = generate_recommendations(user_data, vae)
# The ‘recommendations’ array will contain predicted interaction probabilities for each item.
# We can then use this information to recommend the top items to the user.
Generative Adversarial Network (GAN):
Let us understand some basic things about GAN.
GANs are a powerful class of generative models that learn to generate new data that resembles a given dataset.
GAN contains the following components:
1.Generator (G): The generator takes random noise as input and transforms it into data samples that resemble the training data.
2.Discriminator (D): The discriminator acts as a binary classifier. It takes data samples as input and tries to distinguish between real data from the training set and fake data generated by the generator.
3.Training Process: Training in GANs takes place alternating the updating of Generator and Discriminator. During each iteration, the generator generates fake data, and the discriminator evaluates both real and fake data, assigning probabilities for each sample being real
4.Loss Function: The generator’s loss is inversely related to the discriminator’s accuracy. The generator aims to minimize the log-probability that the discriminator assigns to the generated data being fake. On the other hand, the discriminator aims to maximize the log-probability of assigning the correct labels to real and fake data.
5.The training process continues iteratively until the generator produces realistic data samples that can deceive the discriminator effectively. At this point, the generator can be used as a generative model to produce new data that resembles the training data.
Top of Form
Let us now focus on GAN for recommended system and how it works:
1.Data Representation:
Convert user-item interactions into a matrix format, where rows represent users, columns represent items, and the entries contain user-item interactions (e.g., ratings, binary indicators, or other relevant metrics).
2.GAN Architecture:
- Generator (G): The generator network takes random noise or user/item embeddings as input and generates a recommendation vector for each user. It aims to produce recommendations that are relevant to each user.
- Discriminator (D): The discriminator network takes a user-item pair (user embedding and item embedding) as input and predicts whether the user-item interaction is real (i.e., from the training data) or fake (i.e., generated by the generator).
- The generator and discriminator are trained adversarial, with the generator trying to improve the quality of its recommendations to deceive the discriminator, and the discriminator trying to distinguish between real and generated user-item pairs accurately.
3.Training Process:
- Randomly initialize the generator and discriminator.
- For each training iteration:
1.Sample a batch of real user-item pairs from the training data.
2.Generate a batch of fake user-item pairs using the generator.
3.Train the discriminator on both real and fake pairs, optimizing its ability to distinguish between them.
4.Train the generator, trying to maximize the discriminator’s confusion (minimizing its ability to tell real from fake).
4.Recommendation Generation:
- After training, use the trained generator to produce personalized recommendations for users by inputting their user embeddings or random noise.
- The generator will output a recommendation vector, which can be used to rank items based on their relevance to the user.
Let’s take an example code to understand better:
We are considering Movies Lens dataset and working with it to develop the Recommendation model.
First, we install and import the import packages.
!pip install numpy pandas tensorflow
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from sklearn.model_selection import train_test_split
Loading dataset and doing the preprocessing.
data = pd.read_csv(‘/content/ratings.csv’)
# Preprocess the data to create the user-item interactions matrix
user_item_matrix = data.pivot(index=’userId’, columns=’movieId’, values=’rating’)
user_item_matrix = user_item_matrix.fillna(0)
# Convert the user-item interactions matrix to a NumPy array
user_item_matrix_array = user_item_matrix.to_numpy()
# Spliting the data into train and test sets
train_data, test_data = train_test_split(user_item_matrix_array, test_size=0.3, random_state=10)
Defining parameter and then building architecture of Generator and Discriminator and finally combing these 2 to build the model.
# Define GAN parameters
original_dim = user_item_matrix_array.shape[1] # Number of items (features)
latent_dim = 32 # Number of latent dimensions
batch_size = 64
epochs = 50
# GAN generator architecture
gene_input = Input(shape=(latent_dim,))
gene_x = Dense(128, activation=’relu’)(gene_input)
gene_output = Dense(original_dim, activation=’sigmoid’)(gene_x)
generator = Model(gene_input, gene_output)
# GAN discriminator architecture
disc_input = Input(shape=(original_dim,))
disc_x = Dense(128, activation=’relu’)(disc_input)
disc_output = Dense(1, activation=’sigmoid’)(disc_x)
discriminator = Model(disc_input, disc_output)
# Compile the discriminator
discriminator.compile(optimizer=Adam(beta_1=0.5,learning_rate=0.0002), loss=’binary_crossentropy’)
# Combine the generator and discriminator into a GAN model
gann_input = Input(shape=(latent_dim,))
gann_output = discriminator(generator(gann_input))
gann = Model(gann_input, gann_output)
gann.compile(optimizer=Adam( beta_1=0.5,learning_rate=0.0002), loss=’binary_crossentropy’
Now model will be trained.
# Training the GAN
for epoch in range(epochs):
# random noise generated as input to the generator
noise = np.random.normal(0, 1, size=[batch_size, latent_dim])
# Generate fake data using the generator
generated_dataa = generator.predict(noise)
# Select a random batch of real data from the training set
idx = np.random.randint(0, train_data.shape[0], batch_size)
real_data = train_data[idx]
# Concatenate real and fake data to create the training dataset for the discriminator
X = np.concatenate([real_data, generated_dataa])
# Create labels for the discriminator (1 for real data, 0 for fake data)
y_diss = np.zeros(2 * batch_size)
y_diss[:batch_size] = 0.9 # One-sided label smoothing for stability
# Train the discriminator
discriminator.trainable = True
d_loss = discriminator.train_on_batch(X, y_diss)
# Train the generator
noise = np.random.normal(0, 1, size=[batch_size, latent_dim])
y_genn = np.ones(batch_size)
discriminator.trainable = False
g_loss = gan.train_on_batch(noise, y_genn)
# Use the trained generator to generate recommendations for a user
def generate_recommendation (user_data, generator_model):
return generator_model.predict(user_data)
# Example usage
user_id = 1
user_data = np.expand_dims(user_item_matrix_array[user_id], axis=0)
recommendations = generate_recommendation(user_data, generator)
The ‘recommendations’ array will contain predicted interaction probabilities for each item.
We can then use this information to recommend the top items to the user.
Autoregressive model for Recommendation system
Autoregressive models are another class of generative models that can be used in recommendation systems.
One popular autoregressive model for recommendation is the Recurrent Neural Network (RNN) with sequence-to-sequence architecture.
Let us see how Autoregressive model is used for Recommendation system:
1.Data Preparation: Convert user-item interactions into a sequence of items for each user, ordered by the timestamp or interaction sequence. For example, a user’s interaction history [item1, item2, item3] can be used to predict the next item in the sequence.
2.Autoregressive Model Architecture:
- Encoder: The encoder network processes the input sequence (user’s interaction history) and encodes it into a fixed-length context vector. Common encoder choices include LSTM (Long Short-Term Memory) or GRU (Gated Recurrent Unit) layers.
- Decoder: The decoder network takes the context vector and generates the next item in the sequence, conditioned on the previous items. It can use LSTM or GRU layers, followed by a dense layer with a SoftMax activation to predict the probability distribution over items.
3.Training Process:
- The autoregressive model is trained to minimize the cross-entropy loss between the predicted item probabilities and the ground truth (the actual next item in the sequence).
- During training, the model uses teacher forcing, where the ground truth items are fed as input to the decoder at each time step, instead of using its own generated outputs.
4.Recommendation Generation:
- To generate recommendations for a user, provide the user’s interaction history to the trained model as input.
- Use the model to predict the next item in the sequence.
Repeat the process, conditioning each prediction on the previously generated items, until the desired no. of recommendation is obtained.
#Importing important libraries
import numpy as np
import pandas as pd
from keras.models import Model
from keras.layers import Input, LSTM, Dense
from keras.utils import to_categorical
from sklearn.model_selection import train_test_split
data = pd.read_csv(‘path/to/dataset.csv’)
# Preprocess the data to create the user-item interactions sequences
sequences = data.groupby(‘userId’)[‘movieId’].apply(list).tolist()
# Convert movieId to integer indices (assuming movieIds start from 1)
unique_items = set(item for seq in sequences for item in seq)
item_to_index = {item: index for index, item in enumerate(unique_items)}
sequences_indices = [[item_to_index[item] for item in seq] for seq in sequences]
# Create input and target sequences for training
input_sequences = [seq[:-1] for seq in sequences_indices]
target_sequences = [seq[1:] for seq in sequences_indices]
# Pad sequences to the same length for batch processing of the data
max_sequence_length = max(len(seq) for seq in sequences_indices)
input_sequences = np.array([seq + [0] * (max_sequence_length – len(seq)) for seq in input_sequences])
target_sequences = np.array([seq + [0] * (max_sequence_length – len(seq)) for seq in target_sequences])
# Converting target sequences to one-hot encoded format
target_sequences_onehot = to_categorical(target_sequences, num_classes=len(unique_items))
# Split the data into train and test
train_data, test_data, train_targets, test_targets = train_test_split(input_sequences, target_sequences_onehot, test_size=0.2, random_state=43)
# Define RNN model architecture
latent_dim = 32 # Number of latent dimensions
num_items = len(unique_items)
encoder_inputs = Input(shape=(max_sequence_length,))
encoder = LSTM(latent_dim)(encoder_inputs)
decoder_inputs = Input(shape=(max_sequence_length – 1, num_items))
decoder_lstm = LSTM(latent_dim, return_sequences=True)
decoder_outputs = decoder_lstm(decoder_inputs, initial_state=[encoder, encoder])
decoder_dense = Dense(num_items, activation=’softmax’)
decoder_outputs = decoder_dense(decoder_outputs)
model = Model([encoder_inputs, decoder_inputs], decoder_outputs)
# Compile the model
model.compile(optimizer=’adam’, loss=’categorical_crossentropy’)
# Train the model
model.fit([train_data, train_data[:, 1:]], train_targets,
batch_size=64,
epochs=50,
validation_data=([test_data, test_data[:, 1:]], test_targets))
# Use the trained model to generate recommendations for a user
def generate_recommendations(user_data, model):
# Assuming ‘user_data’ contains the user’s interaction history as a sequence of item indices
# For example: [1, 5, 2, 3, 0, 0, 0] where 0 represents padding
user_data = np.expand_dims(user_data, axis=0)
target_input = np.zeros_like(user_data)
predictions = model.predict([user_data, target_input])
next_item_index = np.argmax(predictions[:, -1, :])
return next_item_index
# Example usage
user_id = 0
user_data = input_sequences[user_id]
next_item_index = generate_recommendations(user_data, model)
next_item = list(unique_items)[next_item_index] print(“Next recommended item:”, next_item)
Conclusion
So, from the blog we got an overall idea what Generative model for Recommended system is. We discussed 3 Recommendation i.e., VAE, GAN, Autoregressive models in brief. We have understood its application using sample dataset of Movies Lens. In practice, the choice of a generative model depends on the specific characteristics of the dataset, the desired recommendation goals, and the available computational resources. Overall, generative models offer a promising direction in the field of recommendation systems, and ongoing research continues to improve their effectiveness and address the challenges associated with their use. Thanks for having patience to read my blog. If you have liked it, please provide feedback in the comment section.