
We are living in the world of data, where data in getting generated every second throughout the world. Data Science has become a critical component of numerous industries and domains due to the increasing availability of data and the need to derive valuable insights from it. As data continues to grow in volume and complexity, data science’s importance will only increase in the coming years. Machine Learning and Deep Learning concepts are gaining wide range of attraction in today’s era. Scikit-learn, also known as Sklearn, is a famous open-source machine learning library for Python, Scikit learn being one of the most important library, is widely used to handle Machine learning algorithms for Data preprocessing, Feature Selection, Model Training, Model Evaluation and more. It offers a comprehensive set of functionalities that make it easier for developers and researchers to implement and experiment with machine learning techniques. We will discuss it more in this blog.
What is Scikit Learn?
It is an open-source library used for handling both supervised and unsupervised Machine Learning algorithms. It offers a powerful toolkit to streamline Machine Learning workflows and thus helping in solving real-world problems effectively.
5 Key Features of Scikit Learn
1. Comprehensive algorithms: It offers a wide collection of supervised and unsupervised learning algorithms, including linear regression, logistic regression, decision trees, random forests, support vector machines (SVM), k-means clustering etc.
2. Preprocessing and feature engineering: Scikit-learn provides various data preprocessing techniques, such as MinMaxScalar for Normalization, StandardScalar for standardization, OneHotEncoder for encoding categorical variables, SimpleImputer for handling missing values and many more. It also offers feature selection and extraction methods to improve model performance.
3. Model Building and Evaluation: Several Machine Learning models are imported using Sklearn library, some of them are Tree based models, Ensemble models, Linear models, SVM based models etc. For Evaluation purposes, Scikit learn is providing metrics such as accuracy, precision, recall, F1 score, and area under the ROC curve (AUC-ROC). It also supports cross-validation and hyperparameter tuning for optimizing model parameters.
4. Integration with other libraries: Scikit-learn integrates with other Python libraries used in data science, such as pandas for data manipulation, matplotlib for visualization, and NumPy for basic numerical calculations and SciPy for advanced numerical calculations.
5. Easy-to-use API: Scikit-learn has a consistent and intuitive API, making it accessible for both beginners and experienced machine learning practitioners.
Data Availability in Scikit Learning:
Some of the data sets are available in this library for direct use. These data sets can be used for practising, exploring various data cleaning techniques, feature selection techniques, model evaluation techniques using scikit learn.
Following Data Sets are available in this library:
1. Iris Dataset: It consists of measurements of sepals and petals of three different species of Iris flowers (Setosa, Versicolor, and Virginica). We need to classify these flowers based on measured values.
2. Boston Housing Dataset: The dataset contains information of housing prices in Boston. It contains 13 attributes and a numerical output variable. It can be used for regression problems.
3. Wine Dataset: The dataset contains chemical analysis of wine. It contains the details such as alcohol content, malic acid, and colour intensity. This dataset is used for classification purpose.
4. Breast Cancer Dataset: Digitized images of breast mass is present in the dataset. The attributes include various characteristics of the cell nuclei, and the task is to classify tumours as benign or malignant.
5. Digit Dataset: The Digit dataset consists of images of handwritten digits (0 to 9). The task is to classify the digit represented by each image.
In addition to these, scikit-learn also provides utilities to load and work with other popular datasets, such as the California housing dataset, MNIST dataset, and more.
How to load a particular dataset?
| import sklearn from sklearn import datasets #datasets imported from sklearn boston_data = datasets.load_boston() ##boston dataset got loaded ##data is getting saved in variable a and b. a = boston_data.data print(a.shape); #(506, 13) b = boston_data.target print(b.shape); #(506,) #we have printed shape |
Sklearn and Preprocessing:
Scikit-learn provides a wide range of preprocessing techniques to prepare and transform your data before feeding it into machine learning algorithms. These preprocessing methods can help with data cleaning, normalization, scaling, encoding categorical variables, handling missing values, and more. Here are some commonly used preprocessing techniques in scikit-learn:
Data Cleaning:
Handling Missing Values: Simple Imputer can be used to replace missing values into different strategy (mean,median,most frequent etc).
| import numpy as np import pandas as pd a=pd.DataFrame({‘A’:[2,3,4],’B’: [3,2,np.NaN]}) a.isna() from sklearn.impute import SimpleImputer mean_imputer = SimpleImputer(missing_values=np.nan, strategy=’mean’) a[“B”] = pd.DataFrame(mean_imputer.fit_transform(a[[“B”]])) |
| BEFORE IMPUTATION – A B 0 False False 1 False False 2 False True |
| AFTER IMPUTATION – A B 0 False False 1 False False 2 False False |
Outlier Detection: Scikit-learn offers various methods, such as the EllipticEnvelope and IsolationForest, for detecting and handling outliers in your data.
Feature Scaling:
- Standardization: The StandardScaler class scales features to have zero mean and unit variance.
- Min-Max Scaling: The MinMaxScaler class scales features to a specified range, usually between 0 and 1.
- Robust Scaling: The RobustScaler scaling technique deals with outliers retension.
We are taking a sample dataset of WindTurbine Failure in the code.
| data=pd.read_csv(‘cleaned_data.csv’) from sklearn.preprocessing import MinMaxScaler data_x=data.loc[:,data.columns!=’Failure_status’] mms=MinMaxScaler() data_x_norm=mms.fit_transform(data_x) data_x_norm=pd.DataFrame(data_x_norm,columns=data_x.columns) |
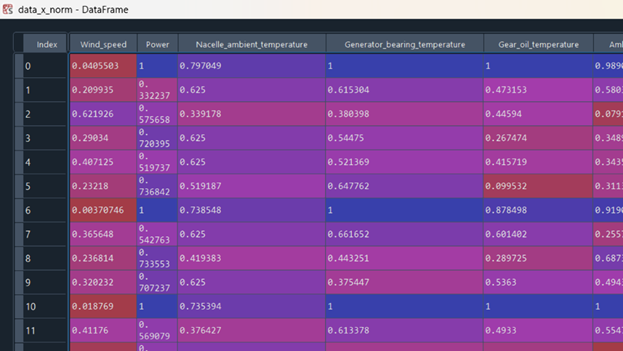
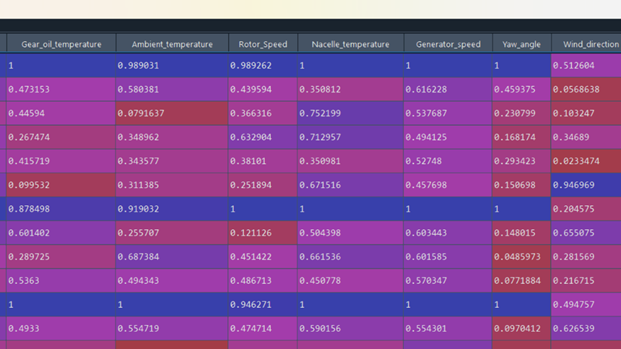
As MinMaxScalar is used, all the values are lying within the range of 0 to 1.
Encoding Categorical Variables:
One-Hot Encoding: The OneHotEncoder class encodes categorical features into binary vectors.
Label Encoding: The Label Encoder class converts categorical labels into integer values.
| purpose | purpose |
| furniture/appliances | 4 |
| furniture/appliances | 4 |
| car0 | 0 |
| car | 1 |
| car | 1 |
| car | 1 |
| car | 1 |
| car | 1 |
| business | 3 |
| business | 3 |
| car | 1 |
| car0 | 0 |
| car | 1 |
| car | 1 |
| car0 | 0 |
| car | 1 |
| business | 3 |
| business | 3 |
| car0 | 0 |
| furniture/appliances | 4 |
| car | 1 |
| furniture/appliances | 4 |
| car0 | 0 |
As you can see before doing encoding, data were present in categorical format and after doing label encoding, data converted to numerical format.
Feature Engineering using Scikit Learn:
In simple words Feature Engineering is all about creating new features by working on existing features. This requires domain knowledge to get a new feature which could be increasing the accuracy of the model.
Dimensionality Reduction:
Principal Component Analysis (PCA): This decreases the number of columns by extracting the features. Correlated input variables become uncorrelated. The attributes which are redundant are removed here. This makes the computation faster.
We are using University sample data in our code for better understanding.
| uni1 = pd.read_excel(“C:/Users/sande/OneDrive/Desktop/DS/Data sets/University_Clustering.xlsx”) pca = PCA(n_components = 6) pca_values = pca.fit_transform(uni_normal) pca_data = pd.DataFrame(pca_values) |
Before doing PCA:
After doing PCA:
Before doing PCA data set was having 8 columns and using PCA, data set got 6 columns.2 columns got extracted out of 8 columns.
Text Processing:
Tokenization: The CountVectorizer and TfidfVectorizer classes convert text documents into numerical feature vectors.
Text Normalization: Scikit-learn provides utilities like CountVectorizer and TfidfVectorizer to perform operations like lowercase conversion, stemming, and stop-word removal.
| from sklearn.feature_extraction.text import CountVectorizer corpus = [‘WWhat is this.’,’What is that’,’What are those’,’What are these’] vectorizer = CountVectorizer() X = vectorizer.fit_transform(corpus) vectorizer.get_feature_names_out() array([‘are’, ‘is’, ‘that’, ‘these’, ‘this’, ‘those’, ‘what’, ‘wwhat’]) print(X.toarray()) output: [[0 1 0 0 1 0 0 1] [0 1 1 0 0 0 1 0] [1 0 0 0 0 1 1 0] [1 0 0 1 0 0 1 0]] |
So, using Sklearn library we imported count vectorizer function which helped in converting text to matrix of token counts.
Sklearn and Pipeline:
Pipelines: It is used to create streamline workflow for Machine Learning task. It helps in connecting multiple preprocessing steps and a final estimator.
Scikit-learn’s Pipeline class allows you to chain together multiple preprocessing steps and a final estimator, enabling you to create a streamlined workflow for your machine learning tasks.
| ###Creating Pipeline from sklearn.pipeline import Pipeline from sklearn.model_selection import cross_val_score mms=MinMaxScaler() mean_imp = SimpleImputer(missing_values=np.nan,strategy=’mean’) model_MNB=MultinomialNB(0.01) preprocessor=Pipeline(steps=[(“imputation_mean”,mean_imp),(“scaler”,mms),(‘PCA’,PCA(n_components=2),(‘model’,model_MNB)]) |
Inside the pipeline we have kept the preprocessing steps and the model we used. This is very useful when we have new data coming, data automatically enters pipeline and the accuracy is delivered without manually doing the preprocessing again and again. Here once new data given, it will check for the missing values and does corresponding imputation, then it standardizes the data, then PCA is done and 2 columns are retained which are not correlated to each other, finally model building process takes place as per the required model.
Model Building using scikit learn:
Machine Learning models are of 3 types, Supervised, Unsupervised and Reinforcement. Under Supervised model many algorithms are imported using Sklearn library, some of them are Tree based models, Ensemble models, Linear models, SVM based models etc. Similarly for Unsupervised model some Clustering algorithms like K Means Clustering, Agglomerative Clustering can be imported using Sklearn library.
These are the few models imported using scikit learn:
| from sklearn.neighbors import KNeighborsClassifier from sklearn.naive_bayes import MultinomialNB from sklearn.naive_bayes import GaussianNB from sklearn.svm import SVC from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import ( AdaBoostClassifier, GradientBoostingClassifier, RandomForestClassifier, BaggingClassifier, ) From sklearn.linear_model import LinearRegression from sklearn.cluster import AgglomerativeClustering from sklearn.cluster import KMeans |
In Supervised model, algorithms are trained using labelled data and here output is present, some of the most popular models are Support Vector Machine, Naïve Bayes, Logistic Regression, Neural Networks etc. In unsupervised learning algorithms are used for unlabelled data, no output is present and no training is done. Unsupervised learning is also known as clustering. Generally Clustering techniques like Agglomerative Clustering (Hierarchical Clustering), K Means clustering (Non-Hierarchical Clustering) used here. Clustering techniques reduces the dimension, data points are grouped here such that data points in the same groups are like each other and dissimilar to data points from other groups. To estimate the number of clusters in KMeans, Scree plot or Elbow curve is used and for Agglomerative clustering, Dendrogram is used.
After model building, Sklearn library is also used to import metrics for model evaluation.
Model Evaluation using scikit learn:
Once model is selected, data is trained and then tested using test data. To know the performance, metrics are required which would help us to know whether our model is good or not, whether it is right fit or not. Several metrics are imported using scikit learn for model evaluation. Few of those are roc_auc_score, mean_squared_error, confusion_matrix,cross_validation_score,accuracy_score,mean_absolute_error.
If there is a classification problem, we often use Accuracy, confusion matrix, log-loss, and AUC-ROC
For Regression problem we often use RMSE, MSE, MAD, MAPE for evaluation
| from sklearn.metrics import confusion_matrix from sklearn.metrics import accuracy_score from sklearn.metrics import roc_auc_score from sklearn.metrics import mean_squared_error, mean_absolute_error pred_y=model.predict(x_test) accuracy_score(pred_y,y_test) |
Sklearn Pandas:
Both the libraries are powerful libraries of Python, used for data analysis, data manipulation and machine learning tasks.
Pandas is used for data manipulation and analysis. To handle structured data efficiently Pandas library provides DataFrame and Series.
Some key features of Pandas are:
- Reading and Writing data in various formats.
- Sorting, Filtering and Aggregating data.
- Merging, joining and reshaping datasets.
- Performing statistical operations on data.
Conclusion:
From this blog we learnt what scikit-learn library is, why it is widely used in Data Science, the data set present in Sklearn, it is applications like Preprocessing, Feature Engineering, Model Building, Model Evaluation, Pipelining, and importance of Pandas and Sklearn in data science community. These were the basic needs of this package; a lot of things are associated with this library at high level. While scikit-learn is a versatile library, it does have some limitations. For instance, it may not be suitable for handling large-scale datasets or deep learning tasks. However, scikit-learn can still be used in conjunction with other libraries to address these limitations. It provides strong foundation for implementing and experimenting with various Machine Learning algorithms and techniques. Almost all the Data Science projects are incomplete without the use of this library. That’s what makes it one of the most popular libraries in the field of Data Science. If you genuinely liked this blog, feel free to give us the feedback in the comment section.